
Vector Sharding: A Predictive, Latency-First Data-Placement Paradigm
No, not that kind of vector... or that kind of sharding.

Introduction
Modern applications face explosive data growth and global distribution. The Internet of Things (IoT), 5G networks, and emerging domains like autonomous vehicles generate data at unprecedented scale. For example, billions of devices continuously produce telemetry (location, speed, sensor streams), and autonomous cars demand millisecond‐scale access to maps, sensor fusion, and contextual data. In fact, industry observers note that “data today is being generated faster than ever before” . Cloud providers now offer vast storage at low cost, enabling “endless amounts of storage space…at a relatively affordable price” . However, data access (not just storage) has become the bottleneck: serving globally distributed, real-time workloads with low latency remains a key challenge.
Traditional data architectures (centralized or statically-sharded databases) struggle to meet these demands. Low-latency applications now require data to be both close to the user and available on demand, even as users and devices move continuously. To address this, we propose Vector Sharding, a novel technique that uses client vectors (multi-dimensional representations of client state, such as location, velocity, and direction) to dynamically place and replicate data. Vector Sharding unifies three strategies – geo-distribution, tiered storage, and predictive modeling – into a single data fabric that is always on and optimized for performance and cost.
As a high-level illustration, consider an edge‐cloud architecture where local servers and central clouds cooperate (Figure below). Edge nodes handle immediate data needs (reducing latency), while the cloud provides massive storage and heavy processing . Vector Sharding enhances this by using real-time telemetry to move data proactively.
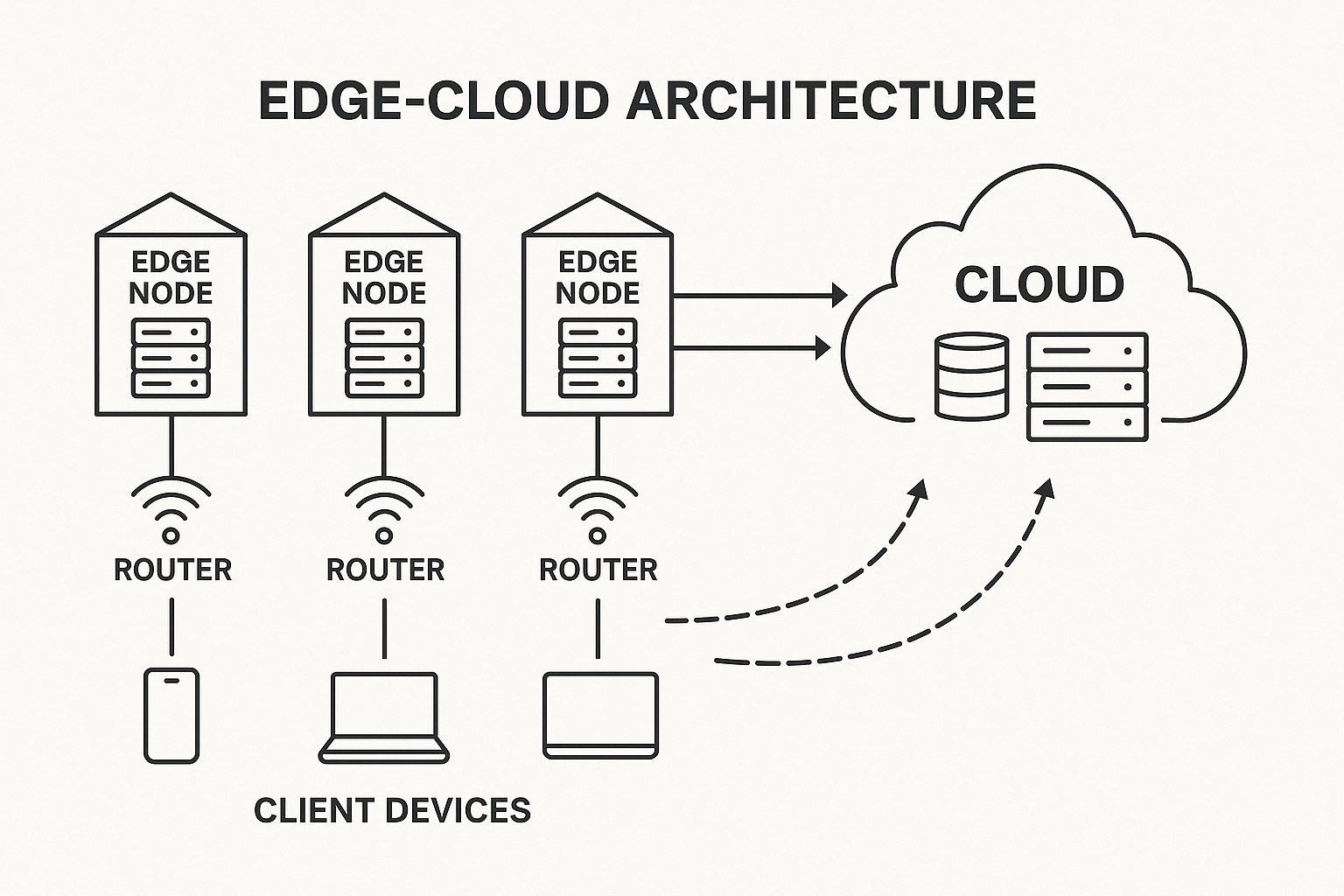
Figure: An edge-cloud architecture distributes computation across edge nodes (closer to devices) and cloud servers. Edge nodes perform local processing and storage, reducing latency for nearby clients, while the cloud provides global storage and scalability .
Limitations of Traditional Sharding
Most existing systems rely on static sharding: data is partitioned by a fixed key (e.g. user ID, region) and minimally replicated. This minimizes storage and synchronization effort, but it also means each data item “lives” in one place (or a small fixed set of replicas). While efficient for scaling large datasets, this approach falls short in globally distributed, dynamic environments. For instance, geographically sharded databases assume that each region’s data is independent ; if not, cross-region queries or movements incur high cost. In practice, user mobility and mixed workload patterns break these assumptions.
A key weakness of static sharding is increased latency for multi-shard queries. As noted in industry analyses, “queries that involve data from multiple shards can experience increased latency because the system must retrieve and combine data from different locations” . In other words, if a user moves into a different region from where its data resides, or if an application query spans multiple partitions, the system must fetch remote data, incurring cross-region network delays. At global scale, network latencies (tens to hundreds of milliseconds) dominate over compute, so even small numbers of remote accesses can ruin performance. Moreover, static sharding is inflexible: once partitioned, adjusting shards for changing hot spots or new usage patterns often requires complex re-sharding and downtime.
In short, minimizing data duplication by static partitioning is no longer sufficient. The “physics of latency” dictates that data must be closer to where it’s needed, not just evenly distributed. As one modern system design guide observes, moving data closer to users “delivers better customer experiences thanks to low-latency data access” . Thus, new strategies must allow selective replication and dynamic placement to serve a fluid, global user base without sacrificing speed.
Defining Vector Sharding
Vector Sharding is defined as a data management technique that uses “client vectors” – e.g. a user’s or device’s current location, velocity, and heading – to guide data placement and replication. The vector concept encapsulates a client’s state in space and time. By interpreting each client’s vector, the system can predict where and when that client will need certain data. Data is then proactively moved or replicated along those vectors.
Unlike conventional sharding (by ID or geography) or exotic schemes (e.g. partitioning by data content), vector sharding continuously adapts to client motion and telemetry. It unifies three strategies into a cohesive framework:
Geo-Distribution – Vector Sharding extends the idea of geo-distributing data by automatically placing copies of data near predicted user locations. Instead of predefining fixed regions, data placement follows the user’s movement vector. By keeping relevant data “within arm’s reach” of the client, latency is minimized .
Tiered Storage – It leverages tiered storage to balance cost and performance. Data expected to be needed soon (near the client’s path) is kept on hot, low-latency storage, while less-critical or idle data is moved to cooler, cheaper tiers . For example, cloud providers offer “hot,” “cool,” and “cold” storage tiers: hot storage has high storage cost but very low access latency; cool and cold tiers have lower storage cost but incur higher retrieval latency . Vector Sharding dynamically migrates data between these tiers based on predicted demand, just as modern object storage systems migrate blobs to appropriate tiers for cost savings .
Predictive Modeling – Finally, Vector Sharding exploits predictive analytics on real-time telemetry to forecast data needs. By analyzing client vectors (and possibly using ML models), the system estimates future data access patterns. This resembles “predictive replica placement” studied in fog/edge computing: for mobile users, replicas of needed data are pre-deployed at expected next locations . In practice, network or application telemetry (GPS traces, cell handovers, usage history) feed these predictions. The result is a proactive data fabric: data is already there when the client arrives.
Together, these elements make Vector Sharding an adaptive, “always-on” data fabric. Instead of static zones, the system continuously tracks clients in the network and uses their vector to orchestrate data flows. Frequently accessed data moves to the nearest edge node (even duplicating if needed), data usage decays into colder tiers when idle, and predictive models ensure overhead is minimized. In effect, Vector Sharding treats each piece of data like a resource that flows through the network along with the user.
Why Static Sharding Fails at Scale
Vector Sharding arises because modern demands outstrip old assumptions. Traditional sharding deliberately minimizes duplication to save storage and synchronization cost. In contrast, Vector Sharding embraces selective duplication as a cheap trade-off. The adage now is: “storage is cheap; latency is expensive.” In many high-performance systems, engineers explicitly trade extra bandwidth or storage for lower response times. For example, redundant queries and caching strategies in web browsers assume “bandwidth is cheap and latency is expensive,” making prefetching worthwhile . Similarly, in distributed data systems, adding replicas costs pennies per gigabyte but can save hundreds of milliseconds per request – a win in user experience and revenue.
Quantitatively, cloud storage can cost a few cents per GB-month, whereas even a few tens of milliseconds of added latency can violate strict SLAs or degrade real-time control loops. Industry analyses now routinely highlight that large cloud providers allow “endless amounts of storage space at a relatively affordable price” . Meanwhile, interactive applications are ultra-sensitive to latency: milliseconds can make the difference between safe and unsafe autonomous driving or a satisfactory user experience.
In this context, static sharding’s frugality becomes a liability. By restricting data to a single location (or few replicas), static shards force clients to fetch remote data when their context changes. This was tolerable in past eras with mostly static user populations. But today’s global, mobile users and 24/7 services demand always-on, local access. Thus we must accept some data duplication. When a vehicle or phone moves, pre-replicating its relevant data to the new region costs gigabytes of cheap storage but saves milliseconds for every request. As one industry expert put it in the context of web services, “adding extra bandwidth that might have been unnecessary…on average saves time” . Vector Sharding simply extends this principle into multi-dimensional data placement: we store extra copies if it cuts down latency.
Tiered Storage Optimization
A core principle of Vector Sharding is hot versus cold data management. Data that is frequently used by active clients should reside on “hot” fast storage, even if that incurs higher cost. Conversely, dormant data can be relegated to “colder” media. Most cloud providers already offer tiered storage for this purpose. For instance, Azure Blob Storage defines:
Hot tier – Highest storage cost, lowest access latency. Used for data that must be read/written frequently .
Cool tier – Lower storage cost, higher access cost. For infrequently accessed data that still needs to be immediately online .
Cold tier (Archive) – Lowest storage cost but much higher retrieval latency (minutes to hours) . Data in this tier is essentially offline unless explicitly rehydrated.
Vector Sharding leverages these concepts dynamically. When a client’s vector indicates it’s approaching a certain region, data relevant to it is promoted to hot/online tiers in the local edge data center (even if a “query-first” system would have left it in cold storage). Conversely, when a client has not been seen or is moving away, its associated data can be demoted: moved out of edge cache into a central cloud or even cold archive. This tiering conserves cost while still allowing rapid reinstatement later. Indeed, cloud documentation notes that archived data “can take up to 15 hours” to retrieve when rehydrated – an acceptable delay during long idle periods, but intolerable during active use. Vector Sharding would trigger that rehydration before the client returns, based on predicted arrival.
By combining tiered storage with predictive placement, Vector Sharding creates a resilient storage hierarchy. Inactive data quietly retires to the lowest-cost tier; when the system’s model sees a likely future need, it orchestrates migration back into fast storage. In this way, data placement continuously shifts between hot and cold tiers based on client vectors, ensuring that the system is both cost-efficient and responsive.
Unifying Geo-Distribution and Predictive Replication
Vector Sharding fundamentally extends the idea of geo-distribution. Instead of static regional shards, data is geographically replicated to follow the user. For example, if a user travels eastbound at 60 mph on a highway, Vector Sharding will pre-stage the user’s profile and working dataset at upcoming edge servers along their route. This is akin to treating the client’s location and velocity as a “ray” and pushing data ahead of it.
Research in fog computing echoes this approach. Bellmann et al. describe predictive replica placement for mobile users: “low latency access to [mobile clients’] data can only be achieved by storing it in their close physical proximity,” so systems must “predict both client movement and pauses in data consumption” . They demonstrate that Markov-model algorithms on the client side can improve local data availability without global replication overhead . Vector Sharding adopts this insight in a broader context: we use movement and telemetry from network infrastructure (GPS, signal triangulation, or historical mobility models) to anticipate where each client will need which data.
The result is a highly localized data layout. By placing data near end-users, customer experiences improve significantly thanks to shorter paths . A geo-distributed system example from industry notes that data placed “in close proximity to end-users” yields low latency and also resilience to failures . In Vector Sharding, we take that further: data is not only statically near users, but dynamically tracks them. When one cluster of users thins out (e.g. night time in one city), data can be evacuated to cheaper storage, then reshuffled when another cluster forms (rush hour in another city). This predictive geo-replication breaks with the static “one shard per region” model and instead creates a continuous geo-data mesh guided by client vectors.
Simultaneously, Vector Sharding employs local caches and prefetches along these vectors. Much like a content delivery network (CDN) pushes popular content to edge PoPs, here we push personalized or stateful data. Edge devices and gateways will cache data locally, minimizing the need to re-fetch from the cloud on every request . This approach has been validated in edge architectures: caching and prefetching strategies “minimize latency” by storing frequently accessed data close to the edge . In practice, each edge node might maintain a working set of data for passing users, evicting it back to the cloud when they depart.
How I Learned To Stop Worrying And Love (Or At Least Accept) Data Duplication
A central tenet of Vector Sharding is that some duplication is worthwhile if it reduces latency. The system intentionally creates extra copies of data along predicted paths. Given modern storage economics, this trade-off often pays off. For example, cloud object storage costs on the order of fractions of a cent per GB-hour, whereas a single 100 ms latency penalty per query can translate to user dissatisfaction or SLA violations. Engineering discussions often emphasize exactly this: adding even redundant transfers (doubling bandwidth usage) is acceptable because “bandwidth is cheap and latency is expensive” .
Concretely, consider a fleet of autonomous vehicles. Storing 1 GB of map updates or sensor logs at multiple edge nodes might cost a few dollars per month (or less), while failing to have that data locally might introduce hundreds of milliseconds per request. A study of network latency strategies observed that extra network traffic is a “good tradeoff” for saved time . Thus, Vector Sharding flips the classical database motto: instead of “don’t replicate to save space,” it says “let’s replicate smartly to save time.” After all, in 5G and cloud contexts, storage is commoditized – what really matters is response time.
Vector Sharding therefore allows selective replication beyond traditional designs. It does not fully mirror entire datasets globally (which would waste space), but it does create copies of actively needed data in multiple locations, tolerating some redundancy. This selective duplication – akin to creating a “hot copy” of a database shard in a second region whenever many users move there – dramatically cuts access time. As an industry blog on replication vs. sharding notes, replication improves performance “by distributing reads among replicas and reducing load on the primary,” at the cost of using more hardware . Vector Sharding generalizes this: more replicas where needed, fewer where not needed.
Resiliency via Dynamic Tiering
Vector Sharding also enhances fault tolerance and data resiliency through dynamic relocation. Since clients come and go, data can be elastic. When a client becomes idle (no recent activity) or travels to another region, its local data copies can be demoted to cooler storage. For instance, an autonomous car parked at night no longer needs a nearby copy of its warm map data; that copy can be moved to a distant data center or cloud archive. The data isn’t lost – it’s simply archived until needed again. Because the system tracks client vectors, it can rehydrate the data when the client reappears.
This mirrors archiving practices: rarely-used objects in cloud storage are archived at minimal cost, then re-cached when accessed. In Azure’s model, archived blobs cannot be read until they are rehydrated to a hot or cool tier, which takes time . In Vector Sharding, we anticipate rehydration: for example, if the network sees a vehicle heading toward where its data was archived, it begins the rehydration process so that by the time the car arrives, the data is already on hot storage. Thus, periods of inactivity become windows to move data to the lowest-cost tier, and upcoming activity signals migration back to high-speed stores.
Overall, this yields a resilient data lifecycle. Data “sleeps” in safe, low-cost storage when unneeded, yet can “wake up” nearly instantly when the client comes back into play. This helps in several ways: it tolerates node failures (data in archive survives disasters), reduces resource use during lulls, and aligns costs with actual usage. In effect, the system behaves like a self-healing cloud: data is never truly gone, but is fluidly redistributed based on demand predictions.
Use Case: 5G-Enabled Autonomous Vehicles
To illustrate Vector Sharding in action, consider the case of self-driving cars. They both produce and consume massive data streams – from HD maps, LIDAR points, to infotainment – all of which must be accessed with minimal delay. 5G edge computing (MEC) and network telemetry provide the fuel for Vector Sharding in this domain.
In this scenario, network telemetry is king. The 5G network continuously tracks each vehicle’s location, heading, and speed through cell tower handoffs and onboard GPS. This real-time vector is fed into the data fabric’s predictive engine. Suppose a car is traveling north at 60 mph; the system predicts it will soon enter a neighboring city or highway corridor. Ahead of time, the data fabric replicates that car’s personalized data (route plans, map tiles, cached sensor models) to the edge servers covering that area. Meanwhile, the edge nodes near the car’s current position keep their caches warm with the car’s data. As the car crosses into a new cell, it seamlessly accesses its data from the local edge node, with latency measured in single-digit milliseconds.
The underlying architecture (see figure) relies on 5G base stations, multi-access edge compute (MEC) servers, and a cloud backend. Vehicles (or their gateways) connect via NB-IoT/5G to MEC nodes which handle local data processing and caching . These MEC nodes are interconnected and linked to central cloud storage. Critically, the Vector Sharding layer sits atop this, moving data between cloud and MEC based on vehicle vectors. In effect, the network becomes an intelligent data fabric that anticipates each vehicle’s needs.
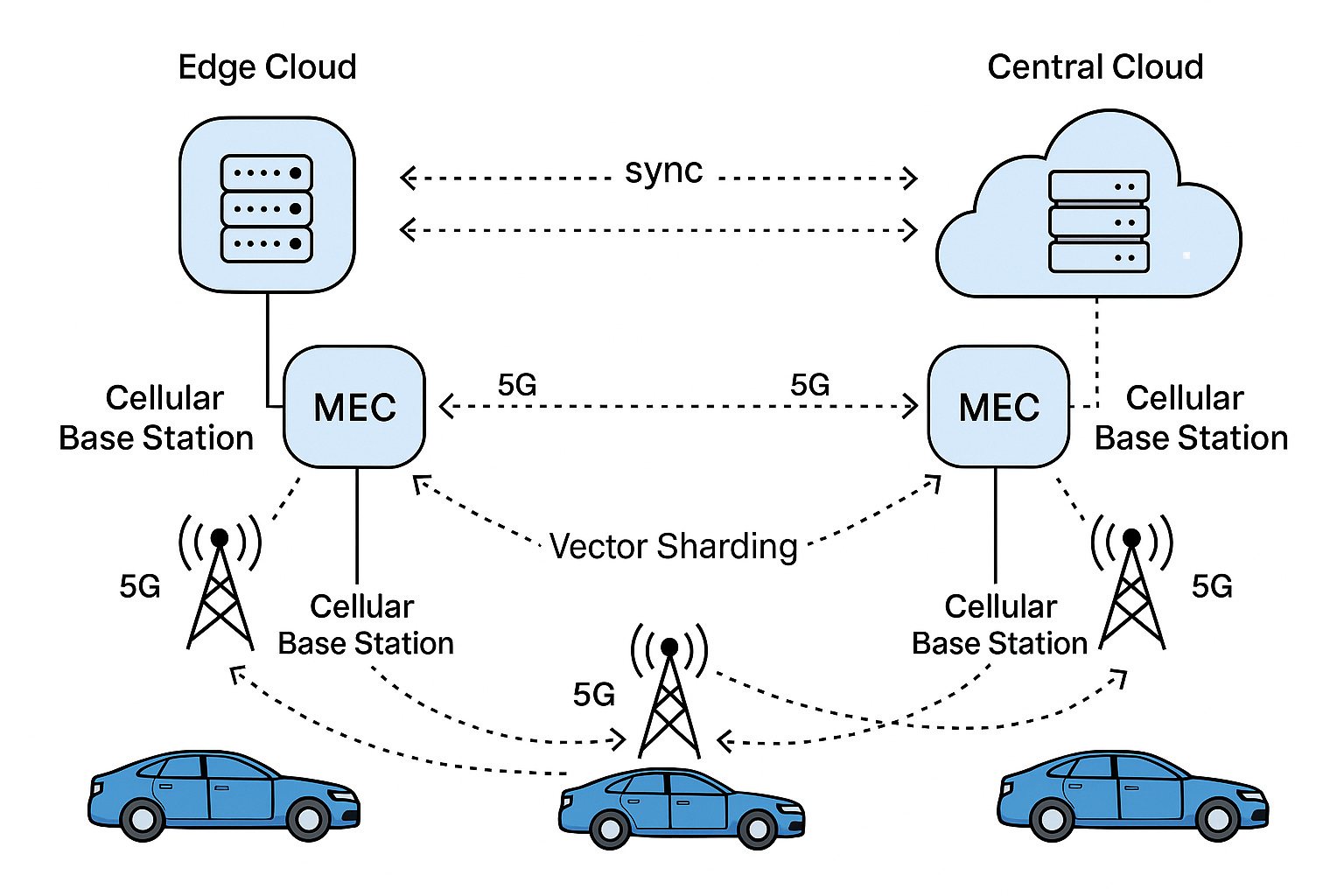
Figure: An example architecture for 5G-connected vehicles and edge compute. Cars (bottom) communicate via a cellular base station to a nearby MEC (edge cloud) node, which caches relevant data. The MEC nodes sync with central cloud servers. Vector Sharding would push data along the vehicles’ predicted paths to adjacent MEC nodes in advance. (Adapted from edge-vehicle architectures .)
This approach yields several benefits:
Always-on low latency. Critical driving data is always served by the nearest edge server. With 5G/MEC, end-to-end latencies can be under 10 ms , improving safety.
High throughput. 5G provides massive bandwidth (100× 4G ), so moving replicas ahead is fast. The bandwidth tradeoff is negligible compared to user delay.
Cost efficiency. Data is only held on expensive edge nodes when needed; when vehicles finish a trip or park, their data demotes to central cold storage. Network telemetry indicates vehicle inactivity, so the system can automatically purge or archive data.
Scalability. As more vehicles join, each is treated similarly. Data for different cars can share edges if their routes converge, or diverge into different nodes if routes split. The fabric self-load-balances based on usage.
In effect, Verizon’s network becomes an “always-on distributed data fabric.” Just as fleet management studies highlight that 5G removes barriers to real-time tracking and low-latency V2X communication , Vector Sharding leverages those features for data management. This ensures that as autonomous vehicles roam the network, the data behind them stays in step, enabling safer, faster operations at lower overall cost.
Future Directions in Architecture
Vector Sharding points to a broader evolution in system design. Modern application architectures must treat data placement as a first-class concern. Microservices, event-driven pipelines, and edge/cloud layers are already in play, but now data locality and movement become critical knobs. Rather than abstract databases behind service calls, architectures will incorporate data mobility orchestration: services request not just queries, but data placement hints.
Under Vector Sharding, key principles emerge:
Data Fabric Mindset. View the global system as a fabric of storage nodes. Data flows across the fabric under control of user-centric policies. This unifies edge, cloud, and storage tiers.
Telemetry-Driven Orchestration. Integrate network and application telemetry (GPS, load, user patterns) into the placement engine. This transforms raw metrics into placement decisions.
Resilient Tiering. Embrace dynamic tiering and rehydration. For example, automating moves to archive during idle times and triggering re-cache on demand.
Selective Consistency. Accept that strict global consistency may be relaxed in favor of locality. Vector Sharding inherently supports eventual consistency: a data update follows the client’s path, so the “nearest copy” might be slightly stale but will converge.
In conclusion, data placement may be the most critical lever for performance and efficiency in future systems. As one modern engineering guide notes, hybrid edge-cloud architectures “optimize performance, improve reliability, and enable new applications that require low latency and high availability” . Vector Sharding embodies this by ensuring data is where it needs to be, when it needs to be there. Applications can no longer assume a fixed backend; instead, they will rely on a dynamic data fabric that tracks their users. In this way, Vector Sharding promises to be a strategic cornerstone for next-generation distributed systems, where managing data location is as important as managing compute.